
Monitoring LangGraph + Azure OpenAI Extraction at Scale: Hybrid Telemetry, Embedding Drift, and State-Aware Observability.
Running an AI-powered data extraction model in production is less about a single “go‑live” event and more about keeping a complex, distributed system stable under real workloads. Once a LangGraph + Azure OpenAI pipeline moves out of a controlled development environment and into a hybrid Azure/on‑prem setup, subtle issues start to surface: data drift across document types, concept drift in how entities are expressed, and gradual degradation in extraction quality that is easy to miss until downstream teams complain.
In a hybrid architecture, those problems are amplified by the plumbing. On‑prem Apache Airflow is responsible for scraping, preprocessing, and batching documents; Azure hosts the LangGraph orchestration layer and Azure OpenAI for inference. Network jitter on ExpressRoute, misaligned embedding spaces between on‑prem and cloud, and differences in tokenization libraries or model versions can all look like “the model got worse” when the real causes are infrastructure and integration issues.
This article takes a concrete, engineering‑first view of that reality. It focuses on production‑grade monitoring and maintenance for a LangGraph‑based data extraction workflow running across Azure and on‑premises: tracking LangGraph state and checkpoints, instrumenting end‑to‑end telemetry, detecting data and embedding drift, handling Azure OpenAI throttling and timeouts, and building feedback loops that keep the system reliable at scale.
Hybrid architectures introduce complexity that purely cloud-based or on-premises systems don't face. Unlike monolithic deployments, the data extraction pipeline distributes critical functions across geographically separated environments, each operating under fundamentally different observability and failure characteristics. The data extraction pipeline of a hybrid model must address the following operational realities:
A 100ms network jitter across multiple task dependencies can accumulate to 1-2 second delays per DAG execution cycle. If the SLA requires extraction batches to complete within 5 minutes, recurring network degradation silently consumes the scheduling margin. Without latency-aware monitoring, it may observe "Airflow task duration increased by 15%" without realizing the root cause is network saturation, not inefficient code.
This leads to degraded semantic search recall in the AG pipeline. A document stored with on-premises embeddings may fail to retrieve in Azure during inference, causing the LLM to operate with incomplete context. The symptom appears as "extraction accuracy dropped 8% for documents with non-English characters," but the root cause is embedding model misalignment across environments.
If on-premises preprocessing estimates that a document will consume 8,000 tokens based on tiktoken==0.5.1, but Azure inference runs tiktoken==0.7.0, the actual token count during inference may be 8,300, exceeding the cost budgets or context window limits. This manifests as unexpected Azure OpenAI API errors mid-pipeline, partial extractions, or cost overruns without clear attribution. Worse, these mismatches are silent—no obvious error occurs; instead, token utilization metrics gradually drift between environments.
On-premises infrastructure typically lags in observability maturity:
This creates a blind spot: Azure-side anomalies (high LLM latency, token cost spikes) are immediately visible, but on-premises issues (Airflow scheduler CPU saturation, scraper connection pool exhaustion) may go undetected for hours until downstream Azure services start failing. It is observe "LLM inference latency increased" in Azure without realizing the upstream on-premises Airflow scheduler is queued behind 1,000 stalled tasks.
If an extraction fails, correlating the failure across a pipeline split between two geographies becomes difficult. A document may fail extraction in Azure, but you cannot query the raw document on-premises to understand why, because the document itself cannot be transmitted out of the on-premises boundary. Root cause analysis relies on statistical summaries and metadata alone.
Without explicit monitoring for connectivity degradation and cross-environment dependency health, your system may silently degrade to stale inference for hours before anyone notices the Azure connection is down.
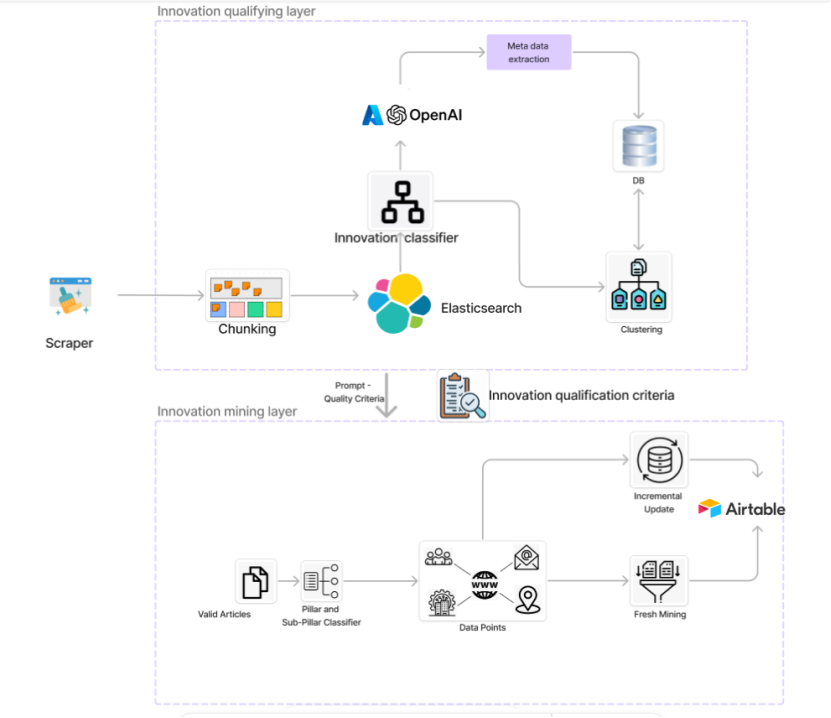
The monitoring platform implements a distributed, hybrid architecture that connects Azure cloud resources with on-premises compute, designed for large-scale ingestion, transformation, and enrichment of innovation data. The architecture is structured to support three core functions: web scraping, NLP-driven text analytics, and LLM-based information extraction.
Separate configuration from code to support environment-specific settings across hybrid deployments.
config.py
**config.py**
```python
import os
from typing import Optional
from pydantic import BaseModel, Field, validator
from pydantic_settings import BaseSettings
class AzureOpenAIConfig(BaseSettings):
"""Azure OpenAI configuration with validation."""
api_key: str = Field(..., env='AZURE_OPENAI_API_KEY')
endpoint: str = Field(..., env='AZURE_OPENAI_ENDPOINT')
deployment_name: str = Field(default='gpt-4o-mini', env='AZURE_OPENAI_DEPLOYMENT')
api_version: str = Field(default='2024-02-15-preview', env='AZURE_OPENAI_API_VERSION')
max_retries: int = Field(default=3, env='AZURE_OPENAI_MAX_RETRIES')
timeout: int = Field(default=60, env='AZURE_OPENAI_TIMEOUT')
@validator('endpoint')
def validate_endpoint(cls, v):
if not v.startswith('https://'):
raise ValueError('Azure OpenAI endpoint must use HTTPS')
return v.rstrip('/')
class Config:
env_file = '.env'
case_sensitive = False
class VectorDBConfig(BaseSettings):
"""Chroma vector database configuration."""
host: str = Field(..., env='CHROMA_HOST')
port: int = Field(default=8000, env='CHROMA_PORT')
collection_name: str = Field(..., env='CHROMA_COLLECTION')
similarity_threshold: float = Field(default=0.75, env='CHROMA_SIMILARITY_THRESHOLD')
max_results: int = Field(default=5, env='CHROMA_MAX_RESULTS')
connection_timeout: int = Field(default=10, env='CHROMA_TIMEOUT')
class Config:
env_file = '.env'
class ElasticsearchConfig(BaseSettings):
"""Elasticsearch configuration for hybrid deployment."""
hosts: list[str] = Field(..., env='ES_HOSTS')
index_name: str = Field(..., env='ES_INDEX')
username: Optional[str] = Field(None, env='ES_USERNAME')
password: Optional[str] = Field(None, env='ES_PASSWORD')
use_ssl: bool = Field(default=True, env='ES_USE_SSL')
verify_certs: bool = Field(default=True, env='ES_VERIFY_CERTS')
timeout: int = Field(default=30, env='ES_TIMEOUT')
class Config:
env_file = '.env'
class MonitoringConfig(BaseSettings):
"""Application Insights and observability configuration."""
instrumentation_key: str = Field(..., env='APPINSIGHTS_INSTRUMENTATION_KEY')
log_level: str = Field(default='INFO', env='LOG_LEVEL')
enable_distributed_tracing: bool = Field(default=True, env='ENABLE_DISTRIBUTED_TRACING')
sample_rate: float = Field(default=1.0, env='TELEMETRY_SAMPLE_RATE')
class Config:
env_file = '.env'
class WorkflowConfig(BaseSettings):
"""Workflow execution parameters."""
max_retries: int = Field(default=3, env='WORKFLOW_MAX_RETRIES')
retry_delay: int = Field(default=5, env='WORKFLOW_RETRY_DELAY')
execution_timeout: int = Field(default=300, env='WORKFLOW_TIMEOUT')
enable_checkpointing: bool = Field(default=True, env='ENABLE_CHECKPOINTING')
checkpoint_backend: str = Field(default='redis', env='CHECKPOINT_BACKEND')
redis_url: Optional[str] = Field(None, env='REDIS_URL')
class Config:
env_file = '.env'
# Global configuration instances
azure_config = AzureOpenAIConfig()
vector_db_config = VectorDBConfig()
es_config = ElasticsearchConfig()
monitoring_config = MonitoringConfig()
workflow_config = WorkflowConfig()
```
Instrument all workflow nodes with Application Insights for hybrid observability.
**telemetry.py**
```python
import time
import functools
import logging
from typing import Any, Callable, Dict
from contextlib import contextmanager
from opencensus.ext.azure.log_exporter import AzureLogHandler
from opencensus.ext.azure.trace_exporter import AzureExporter
from opencensus.trace import config_integration
from opencensus.trace.samplers import ProbabilitySampler
from opencensus.trace.tracer import Tracer
from opencensus.trace.span import SpanKind
from config import monitoring_config
# Configure structured logging
logger = logging.getLogger(__name__)
logger.setLevel(monitoring_config.log_level)
logger.addHandler(AzureLogHandler(
connection_string=f'InstrumentationKey={monitoring_config.instrumentation_key}'
))
# Configure distributed tracing
config_integration.trace_integrations(['requests', 'httplib'])
tracer = Tracer(
exporter=AzureExporter(
connection_string=f'InstrumentationKey={monitoring_config.instrumentation_key}'
),
sampler=ProbabilitySampler(rate=monitoring_config.sample_rate)
)
class WorkflowMetrics:
"""Custom metrics for LangGraph workflow monitoring."""
def __init__(self):
self.node_executions = {}
self.node_failures = {}
self.node_latencies = {}
def record_execution(self, node_name: str, success: bool, duration: float, metadata: Dict[str, Any] = None):
"""Record node execution metrics."""
logger.info(
'Node execution completed',
extra={
'custom_dimensions': {
'node_name': node_name,
'success': success,
'duration_ms': duration * 1000,
'metadata': metadata or {}
}
}
)
if node_name not in self.node_executions:
self.node_executions[node_name] = 0
self.node_failures[node_name] = 0
self.node_latencies[node_name] = []
self.node_executions[node_name] += 1
if not success:
self.node_failures[node_name] += 1
self.node_latencies[node_name].append(duration)
def record_llm_call(self, deployment: str, tokens_used: int, latency: float, status_code: int):
"""Record LLM API call metrics."""
logger.info(
'LLM API call',
extra={
'custom_dimensions': {
'deployment': deployment,
'tokens_used': tokens_used,
'latency_ms': latency * 1000,
'status_code': status_code,
'throttled': status_code == 429
}
}
)
def record_retrieval(self, source: str, query_latency: float, num_results: int, avg_similarity: float):
"""Record vector/text retrieval metrics."""
logger.info(
'Document retrieval',
extra={
'custom_dimensions': {
'source': source,
'query_latency_ms': query_latency * 1000,
'num_results': num_results,
'avg_similarity_score': avg_similarity
}
}
)
def record_validation_failure(self, field_name: str, error_type: str, value: Any = None):
"""Record data quality validation failures."""
logger.warning(
'Validation failure',
extra={
'custom_dimensions': {
'field_name': field_name,
'error_type': error_type,
'invalid_value': str(value) if value else None
}
}
)
workflow_metrics = WorkflowMetrics()
def trace_node(node_name: str):
"""Decorator to add distributed tracing and metrics to workflow nodes."""
def decorator(func: Callable) -> Callable:
@functools.wraps(func)
def wrapper(state: Dict[str, Any]) -> Dict[str, Any]:
with tracer.span(name=f'workflow.node.{node_name}') as span:
span.span_kind = SpanKind.INTERNAL
span.add_attribute('node.name', node_name)
span.add_attribute('correlation_id', state.get('correlation_id', 'unknown'))
start_time = time.time()
success = True
error_message = None
try:
result = func(state)
span.add_attribute('node.output_size', len(str(result)))
return result
except Exception as e:
success = False
error_message = str(e)
span.add_attribute('error', True)
span.add_attribute('error.message', error_message)
logger.error(
f'Node {node_name} failed',
extra={
'custom_dimensions': {
'node_name': node_name,
'error': error_message,
'correlation_id': state.get('correlation_id')
}
},
exc_info=True
)
raise
finally:
duration = time.time() - start_time
workflow_metrics.record_execution(
node_name=node_name,
success=success,
duration=duration,
metadata={'error': error_message} if error_message else None
)
return wrapper
return decorator
@contextmanager
def trace_llm_call(deployment: str, correlation_id: str):
"""Context manager for tracing LLM API calls."""
with tracer.span(name=f'llm.call.{deployment}') as span:
span.span_kind = SpanKind.CLIENT
span.add_attribute('llm.deployment', deployment)
span.add_attribute('correlation_id', correlation_id)
start_time = time.time()
try:
yield span
finally:
latency = time.time() - start_time
span.add_attribute('llm.latency_ms', latency * 1000)
``
Define workflow state with runtime validation to catch schema drift early
**state.py**
```python
from typing import Dict, List, Any, Optional
from typing_extensions import TypedDict
from pydantic import BaseModel, Field, validator
from datetime import datetime
import uuid
class InnovationData(BaseModel):
"""Validated innovation extraction output."""
title: str = Field(..., min_length=1, max_length=500)
description: Optional[str] = Field(None, max_length=5000)
organization: Optional[str] = Field(None, max_length=200)
sector: Optional[str] = None
development_stage: Optional[str] = None
funding_amount: Optional[float] = Field(None, ge=0)
url: Optional[str] = None
extracted_at: datetime = Field(default_factory=datetime.utcnow)
confidence_score: Optional[float] = Field(None, ge=0.0, le=1.0)
@validator('sector')
def validate_sector(cls, v):
allowed_sectors = {'technology', 'healthcare', 'energy', 'finance', 'other'}
if v and v.lower() not in allowed_sectors:
return 'other' # Fallback for unknown sectors
return v.lower() if v else None
class OrganizationData(BaseModel):
"""Validated organization metadata."""
name: str = Field(..., min_length=1)
website: Optional[str] = None
location: Optional[str] = None
employee_count: Optional[int] = Field(None, ge=0)
founded_year: Optional[int] = Field(None, ge=1800, le=datetime.now().year)
class ValidationResult(BaseModel):
"""Data quality validation tracking."""
field_name: str
is_valid: bool
error_type: Optional[str] = None
error_message: Optional[str] = None
validated_at: datetime = Field(default_factory=datetime.utcnow)
class State(TypedDict):
"""Shared memory of the Web Agent workflow."""
# Unique identifier for distributed tracing
correlation_id: str
# Input query and flags
query: Dict[str, str]
flags: Dict[str, bool]
# Retrieved documents and context
documents: List[str]
elasticsearch_results: Optional[List[Dict[str, Any]]]
chroma_results: Optional[List[Dict[str, Any]]]
# Extracted structured data
innovation_data: Optional[InnovationData]
org_data: Optional[OrganizationData]
# Validation and quality tracking
validation_results: List[ValidationResult]
# Execution metadata
execution_start_time: float
node_execution_history: List[str]
retry_count: int
# Error tracking
errors: List[Dict[str, Any]]
def create_initial_state(query: Dict[str, str], flags: Dict[str, bool]) -> State:
"""Factory function to create validated initial state."""
return State(
correlation_id=str(uuid.uuid4()),
query=query,
flags=flags,
documents=[],
elasticsearch_results=None,
chroma_results=None,
innovation_data=None,
org_data=None,
validation_results=[],
execution_start_time=time.time(),
node_execution_history=[],
retry_count=0,
errors=[]
)
```**llm_client.py**
```python
import time
from typing import Dict, Any, Optional
from langchain_openai import AzureChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from tenacity import (
retry,
stop_after_attempt,
wait_exponential,
retry_if_exception_type
)
from requests.exceptions import HTTPError, Timeout, ConnectionError
from config import azure_config
from telemetry import trace_llm_call, workflow_metrics, logger
class RateLimitError(Exception):
"""Raised when Azure OpenAI rate limit is hit."""
pass
class LLMClient:
"""Production-ready Azure OpenAI client with monitoring and resilience."""
def __init__(self):
self.llm = AzureChatOpenAI(
azure_deployment=azure_config.deployment_name,
api_version=azure_config.api_version,
azure_endpoint=azure_config.endpoint,
api_key=azure_config.api_key,
temperature=0.0, # Deterministic for extraction tasks
max_retries=0, # Handle retries manually for better control
timeout=azure_config.timeout
)
self.deployment_name = azure_config.deployment_name
@retry(
stop=stop_after_attempt(azure_config.max_retries),
wait=wait_exponential(multiplier=1, min=4, max=60),
retry=retry_if_exception_type((HTTPError, Timeout, ConnectionError, RateLimitError)),
reraise=True
)
def invoke_with_retry(
self,
system_prompt: str,
user_prompt: str,
correlation_id: str,
metadata: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""Invoke LLM with retry logic and comprehensive telemetry."""
with trace_llm_call(self.deployment_name, correlation_id) as span:
start_time = time.time()
try:
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=user_prompt)
]
# Estimate input tokens (approximate)
estimated_input_tokens = len(system_prompt.split()) + len(user_prompt.split())
span.add_attribute('llm.estimated_input_tokens', estimated_input_tokens)
response = self.llm.invoke(messages)
latency = time.time() - start_time
# Extract token usage if available
tokens_used = 0
if hasattr(response, 'response_metadata'):
token_usage = response.response_metadata.get('token_usage', {})
tokens_used = token_usage.get('total_tokens', 0)
span.add_attribute('llm.prompt_tokens', token_usage.get('prompt_tokens', 0))
span.add_attribute('llm.completion_tokens', token_usage.get('completion_tokens', 0))
workflow_metrics.record_llm_call(
deployment=self.deployment_name,
tokens_used=tokens_used,
latency=latency,
status_code=200
)
return {
'content': response.content,
'tokens_used': tokens_used,
'latency': latency,
'metadata': metadata or {}
}
except HTTPError as e:
if e.response.status_code == 429:
logger.warning(
'Azure OpenAI rate limit hit',
extra={
'custom_dimensions': {
'deployment': self.deployment_name,
'correlation_id': correlation_id
}
}
)
workflow_metrics.record_llm_call(
deployment=self.deployment_name,
tokens_used=0,
latency=time.time() - start_time,
status_code=429
)
raise RateLimitError('Azure OpenAI rate limit exceeded') from e
raise
except Exception as e:
logger.error(
'LLM invocation failed',
extra={
'custom_dimensions': {
'deployment': self.deployment_name,
'correlation_id': correlation_id,
'error': str(e)
}
},
exc_info=True
)
raise
llm_client = LLMClient()
```
**retrieval.py**
```python
import time
from typing import List, Dict, Any, Optional
from elasticsearch import Elasticsearch
import chromadb
from chromadb.config import Settings
from tenacity import retry, stop_after_attempt, wait_exponential
from config import vector_db_config, es_config
from telemetry import workflow_metrics, logger, tracer
from state import State
class HybridRetriever:
"""Production retrieval combining Elasticsearch and Chroma with observability."""
def __init__(self):
# Elasticsearch client for on-premises full-text search
self.es_client = Elasticsearch(
hosts=es_config.hosts,
basic_auth=(es_config.username, es_config.password) if es_config.username else None,
use_ssl=es_config.use_ssl,
verify_certs=es_config.verify_certs,
timeout=es_config.timeout
)
# Chroma client for semantic vector search
self.chroma_client = chromadb.HttpClient(
host=vector_db_config.host,
port=vector_db_config.port,
settings=Settings(
anonymized_telemetry=False,
allow_reset=False
)
)
self.collection = self.chroma_client.get_collection(
name=vector_db_config.collection_name
)
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=10)
)
def retrieve_from_elasticsearch(
self,
query: str,
correlation_id: str,
filters: Optional[Dict[str, Any]] = None,
max_results: int = 10
) -> List[Dict[str, Any]]:
"""Retrieve documents from on-premises Elasticsearch with telemetry."""
with tracer.span(name='retrieval.elasticsearch') as span:
span.add_attribute('correlation_id', correlation_id)
span.add_attribute('query_length', len(query))
start_time = time.time()
try:
# Build query
es_query = {
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": query,
"fields": ["title^3", "description^2", "content"],
"type": "best_fields",
"fuzziness": "AUTO"
}
}
]
}
},
"size": max_results,
"_source": ["title", "description", "url", "sector", "timestamp"]
}
# Add filters if provided
if filters:
es_query["query"]["bool"]["filter"] = [
{"term": {k: v}} for k, v in filters.items()
]
response = self.es_client.search(
index=es_config.index_name,
body=es_query
)
latency = time.time() - start_time
num_results = len(response['hits']['hits'])
# Extract results
documents = []
for hit in response['hits']['hits']:
documents.append({
'content': hit['_source'].get('description', ''),
'title': hit['_source'].get('title', ''),
'url': hit['_source'].get('url', ''),
'score': hit['_score'],
'metadata': hit['_source']
})
# Record metrics
workflow_metrics.record_retrieval(
source='elasticsearch',
query_latency=latency,
num_results=num_results,
avg_similarity=sum(d['score'] for d in documents) / num_results if num_results > 0 else 0
)
span.add_attribute('results_count', num_results)
span.add_attribute('latency_ms', latency * 1000)
logger.info(
'Elasticsearch retrieval completed',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'num_results': num_results,
'latency_ms': latency * 1000,
'query': query[:100] # Truncate for logging
}
}
)
return documents
except Exception as e:
logger.error(
'Elasticsearch retrieval failed',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'error': str(e),
'query': query[:100]
}
},
exc_info=True
)
# Return empty list on failure to allow graceful degradation
return []
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=10)
)
def retrieve_from_chroma(
self,
query: str,
correlation_id: str,
max_results: Optional[int] = None,
where_filter: Optional[Dict[str, Any]] = None
) -> List[Dict[str, Any]]:
"""Retrieve semantically similar documents from Chroma with telemetry."""
with tracer.span(name='retrieval.chroma') as span:
span.add_attribute('correlation_id', correlation_id)
span.add_attribute('query_length', len(query))
start_time = time.time()
try:
n_results = max_results or vector_db_config.max_results
results = self.collection.query(
query_texts=[query],
n_results=n_results,
where=where_filter,
include=['documents', 'metadatas', 'distances']
)
latency = time.time() - start_time
# Process results
documents = []
if results['documents'] and len(results['documents'][0]) > 0:
for i, doc in enumerate(results['documents'][0]):
# Convert distance to similarity score (1 - normalized distance)
distance = results['distances'][0][i]
similarity = 1 / (1 + distance) # Convert L2 distance to similarity
# Filter by similarity threshold
if similarity >= vector_db_config.similarity_threshold:
documents.append({
'content': doc,
'similarity': similarity,
'distance': distance,
'metadata': results['metadatas'][0][i] if results['metadatas'] else {}
})
num_results = len(documents)
avg_similarity = sum(d['similarity'] for d in documents) / num_results if num_results > 0 else 0
# Record metrics
workflow_metrics.record_retrieval(
source='chroma',
query_latency=latency,
num_results=num_results,
avg_similarity=avg_similarity
)
span.add_attribute('results_count', num_results)
span.add_attribute('latency_ms', latency * 1000)
span.add_attribute('avg_similarity', avg_similarity)
logger.info(
'Chroma retrieval completed',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'num_results': num_results,
'latency_ms': latency * 1000,
'avg_similarity': avg_similarity,
'query': query[:100]
}
}
)
# Alert on low similarity scores
if num_results > 0 and avg_similarity < 0.6:
logger.warning(
'Low semantic similarity in Chroma results',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'avg_similarity': avg_similarity,
'threshold': vector_db_config.similarity_threshold
}
}
)
return documents
except Exception as e:
logger.error(
'Chroma retrieval failed',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'error': str(e),
'query': query[:100]
}
},
exc_info=True
)
return []
# Global retriever instance
hybrid_retriever = HybridRetriever()
```
**workflow_nodes.py**
```python
import json
from typing import Dict, Any
from pydantic import ValidationError
from state import State, InnovationData, OrganizationData, ValidationResult
from llm_client import llm_client
from retrieval import hybrid_retriever
from telemetry import trace_node, workflow_metrics, logger
@trace_node('validate_source')
def validate_source(state: State) -> Dict[str, Any]:
"""Validate input source and set workflow routing flags."""
correlation_id = state['correlation_id']
query = state.get('query', {})
# Check if HTML content flag is provided
html_flag = state['flags'].get('HTML_flag', False)
org_flag = state['flags'].get('org_flag', False)
# Validate query structure
if not query or not query.get('innovation'):
logger.error(
'Invalid query structure',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'query': query
}
}
)
return {
'flags': {'error': True},
'errors': [{'node': 'validate_source', 'message': 'Missing innovation query'}]
}
state['node_execution_history'].append('validate_source')
return {
'flags': {'HTML_flag': html_flag, 'org_flag': org_flag, 'validated': True},
'node_execution_history': state['node_execution_history']
}
@trace_node('retrieve_innovation')
def retrieve_innovation_docs(state: State) -> Dict[str, Any]:
"""Retrieve relevant innovation documents using hybrid search strategy."""
correlation_id = state['correlation_id']
query_text = state['query'].get('innovation', '')
# Perform hybrid retrieval
es_docs = hybrid_retriever.retrieve_from_elasticsearch(
query=query_text,
correlation_id=correlation_id,
max_results=10
)
chroma_docs = hybrid_retriever.retrieve_from_chroma(
query=query_text,
correlation_id=correlation_id,
max_results=5
)
# Combine and deduplicate results
all_docs = es_docs + chroma_docs
# Alert if retrieval yields no results
if not all_docs:
logger.warning(
'No documents retrieved for innovation query',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'query': query_text[:100]
}
}
)
workflow_metrics.record_validation_failure(
field_name='document_retrieval',
error_type='no_results',
value=query_text
)
state['node_execution_history'].append('retrieve_innovation')
return {
'documents': [doc.get('content', '') for doc in all_docs],
'elasticsearch_results': es_docs,
'chroma_results': chroma_docs,
'node_execution_history': state['node_execution_history']
}
@trace_node('extract_innovation')
def extract_innovation_data(state: State) -> Dict[str, Any]:
"""Extract structured innovation data using LLM with RAG context."""
correlation_id = state['correlation_id']
query_text = state['query'].get('innovation', '')
documents = state.get('documents', [])
# Prepare context from retrieved documents
context = '\n\n'.join([f"Document {i+1}:\n{doc}" for i, doc in enumerate(documents[:5])])
if not context:
context = "No relevant context documents available."
logger.warning(
'Extracting innovation without context',
extra={'custom_dimensions': {'correlation_id': correlation_id}}
)
system_prompt = """You are an expert at extracting structured innovation data from unstructured text.
Extract the following fields in valid JSON format:
- title (string, required): Name of the innovation
- description (string): Detailed description
- organization (string): Organization developing the innovation
- sector (string): Industry sector (technology/healthcare/energy/finance/other)
- development_stage (string): Current stage (research/prototype/production/other)
- funding_amount (number): Funding in USD if mentioned
- url (string): Relevant URL if available
Return ONLY valid JSON with these fields. Use null for missing values."""
user_prompt = f"""Query: {query_text}
Context Documents:
{context}
Extract innovation data as JSON:"""
try:
llm_response = llm_client.invoke_with_retry(
system_prompt=system_prompt,
user_prompt=user_prompt,
correlation_id=correlation_id,
metadata={'query': query_text}
)
# Parse and validate LLM response
content = llm_response['content']
try:
parsed_data = json.loads(content)
innovation = InnovationData(**parsed_data)
state['node_execution_history'].append('extract_innovation')
return {
'innovation_data': innovation,
'node_execution_history': state['node_execution_history']
}
except json.JSONDecodeError as e:
logger.error(
'LLM returned invalid JSON',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'llm_response': content[:500],
'error': str(e)
}
}
)
workflow_metrics.record_validation_failure(
field_name='llm_output',
error_type='invalid_json',
value=content[:200]
)
raise
except ValidationError as e:
logger.error(
'Innovation data validation failed',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'validation_errors': e.errors(),
'data': parsed_data
}
}
)
# Record field-level validation failures
for error in e.errors():
workflow_metrics.record_validation_failure(
field_name='.'.join(str(loc) for loc in error['loc']),
error_type=error['type'],
value=error.get('input')
)
raise
except Exception as e:
logger.error(
'Innovation extraction failed',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'error': str(e)
}
},
exc_info=True
)
state['errors'].append({
'node': 'extract_innovation',
'error': str(e),
'query': query_text
})
return {'errors': state['errors']}
@trace_node('pipeline_decision')
def pipeline_decision(state: State) -> str:
"""Determine workflow routing based on flags and state."""
html_flag = state['flags'].get('HTML_flag', False)
org_flag = state['flags'].get('org_flag', False)
error_flag = state['flags'].get('error', False)
# Route to error handler if validation failed
if error_flag:
return 'error_handler'
# Determine routing logic
if html_flag and org_flag:
return 'innovation_only'
elif html_flag:
return 'innovation_plus_org'
elif org_flag:
return 'direct_org_wrapper'
else:
return 'open_search_mode'
@trace_node('validate_results')
def validate_results(state: State) -> Dict[str, Any]:
"""Validate extracted data quality and completeness."""
correlation_id = state['correlation_id']
validation_results = []
innovation_data = state.get('innovation_data')
if innovation_data:
# Check required fields
if not innovation_data.title:
validation_results.append(ValidationResult(
field_name='title',
is_valid=False,
error_type='missing_required',
error_message='Title is required but missing'
))
workflow_metrics.record_validation_failure('title', 'missing_required')
# Check confidence score if available
if innovation_data.confidence_score and innovation_data.confidence_score < 0.5:
validation_results.append(ValidationResult(
field_name='confidence_score',
is_valid=False,
error_type='low_confidence',
error_message=f'Confidence score {innovation_data.confidence_score} below threshold'
))
logger.warning(
'Low confidence in extraction',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'confidence': innovation_data.confidence_score
}
}
)
state['node_execution_history'].append('validate_results')
return {
'validation_results': validation_results,
'node_execution_history': state['node_execution_history']
}
```**workflow.py**
```python
import time
from typing import Dict, Any
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from langgraph.checkpoint.redis import RedisSaver
from state import State, create_initial_state
from workflow_nodes import (
validate_source,
retrieve_innovation_docs,
extract_innovation_data,
pipeline_decision,
validate_results
)
from config import workflow_config
from telemetry import logger, tracer
class ProductionWorkflow:
"""Production-ready LangGraph workflow with checkpointing and monitoring."""
def __init__(self):
self.graph = self._build_graph()
def _build_graph(self) -> StateGraph:
"""Construct the LangGraph workflow with all nodes and edges."""
builder = StateGraph(State)
# Add workflow nodes
builder.add_node('validate_source', validate_source)
builder.add_node('retrieve_innovation', retrieve_innovation_docs)
builder.add_node('extract_innovation', extract_innovation_data)
builder.add_node('validate_results', validate_results)
builder.add_node('final_wrapper', self._wrap_output)
builder.add_node('error_handler', self._handle_error)
# Define workflow edges
builder.add_edge(START, 'validate_source')
# Conditional routing based on source validation
builder.add_conditional_edges(
'validate_source',
pipeline_decision,
{
'innovation_only': 'retrieve_innovation',
'innovation_plus_org': 'retrieve_innovation',
'direct_org_wrapper': 'final_wrapper',
'open_search_mode': 'retrieve_innovation',
'error_handler': 'error_handler'
}
)
# Linear flow for innovation extraction
builder.add_edge('retrieve_innovation', 'extract_innovation')
builder.add_edge('extract_innovation', 'validate_results')
builder.add_edge('validate_results', 'final_wrapper')
# Error handler routes to end
builder.add_edge('error_handler', END)
builder.add_edge('final_wrapper', END)
# Configure checkpointing for resilience
if workflow_config.enable_checkpointing:
if workflow_config.checkpoint_backend == 'redis' and workflow_config.redis_url:
checkpointer = RedisSaver.from_conn_string(workflow_config.redis_url)
else:
checkpointer = MemorySaver()
return builder.compile(checkpointer=checkpointer)
else:
return builder.compile()
@staticmethod
def _wrap_output(state: State) -> Dict[str, Any]:
"""Prepare final output with metadata."""
execution_time = time.time() - state['execution_start_time']
output = {
'correlation_id': state['correlation_id'],
'innovation_data': state.get('innovation_data'),
'org_data': state.get('org_data'),
'validation_results': state.get('validation_results', []),
'execution_metadata': {
'duration_seconds': execution_time,
'nodes_executed': state['node_execution_history'],
'retry_count': state.get('retry_count', 0),
'errors': state.get('errors', [])
}
}
logger.info(
'Workflow completed successfully',
extra={
'custom_dimensions': {
'correlation_id': state['correlation_id'],
'duration_seconds': execution_time,
'nodes_executed': len(state['node_execution_history'])
}
}
)
state['node_execution_history'].append('final_wrapper')
return {'node_execution_history': state['node_execution_history']}
@staticmethod
def _handle_error(state: State) -> Dict[str, Any]:
"""Handle workflow errors with logging and alerting."""
errors = state.get('errors', [])
logger.error(
'Workflow failed with errors',
extra={
'custom_dimensions': {
'correlation_id': state['correlation_id'],
'errors': errors,
'nodes_executed': state['node_execution_history']
}
}
)
state['node_execution_history'].append('error_handler')
return {'node_execution_history': state['node_execution_history']}
def execute(
self,
query: Dict[str, str],
flags: Dict[str, bool],
thread_id: str = None
) -> Dict[str, Any]:
"""Execute workflow with comprehensive error handling and tracing."""
# Create initial state
initial_state = create_initial_state(query=query, flags=flags)
correlation_id = initial_state['correlation_id']
with tracer.span(name='workflow.execution') as span:
span.add_attribute('correlation_id', correlation_id)
span.add_attribute('query', str(query)[:100])
try:
# Execute workflow
config = {'configurable': {'thread_id': thread_id}} if thread_id else {}
result = self.graph.invoke(
initial_state,
config=config
)
span.add_attribute('success', True)
span.add_attribute('execution_time', time.time() - initial_state['execution_start_time'])
return result
except Exception as e:
span.add_attribute('success', False)
span.add_attribute('error', str(e))
logger.error(
'Workflow execution failed',
extra={
'custom_dimensions': {
'correlation_id': correlation_id,
'error': str(e),
'query': query
}
},
exc_info=True
)
raise
# Global workflow instance
production_workflow = ProductionWorkflow()
```
**main.py**
```python
import sys
from workflow import production_workflow
from telemetry import logger
def main():
"""Example production usage with comprehensive error handling."""
# Example 1: Innovation extraction with HTML source
query_1 = {
'query': {'innovation': 'AI-powered renewable energy optimization system'},
'flags': {'HTML_flag': True, 'org_flag': False}
}
try:
logger.info('Starting workflow execution', extra={'custom_dimensions': {'example': 'innovation_extraction'}})
result = production_workflow.execute(
query=query_1['query'],
flags=query_1['flags'],
thread_id='example-thread-1'
)
# Access results
innovation = result.get('innovation_data')
if innovation:
print(f"Extracted Innovation: {innovation.title}")
print(f"Organization: {innovation.organization}")
print(f"Confidence: {innovation.confidence_score}")
# Check validation results
validation_issues = [v for v in result.get('validation_results', []) if not v.is_valid]
if validation_issues:
logger.warning(
'Validation issues detected',
extra={
'custom_dimensions': {
'issues': [v.dict() for v in validation_issues]
}
}
)
# Review execution metadata
metadata = result.get('execution_metadata', {})
print(f"Execution time: {metadata.get('duration_seconds', 0):.2f}s")
print(f"Nodes executed: {metadata.get('nodes_executed', [])}")
except Exception as e:
logger.error('Workflow execution failed', exc_info=True)
sys.exit(1)
# Example 2: Direct organization extraction
query_2 = {
'query': {'organization': 'Tesla Energy Division'},
'flags': {'HTML_flag': False, 'org_flag': True}
}
try:
result = production_workflow.execute(
query=query_2['query'],
flags=query_2['flags'],
thread_id='example-thread-2'
)
org = result.get('org_data')
if org:
print(f"Organization: {org.name}")
print(f"Location: {org.location}")
except Exception as e:
logger.error('Organization extraction failed', exc_info=True)
sys.exit(1)
if __name__ == '__main__':
main()
```
**.env.example**
```bash
# Azure OpenAI Configuration
AZURE_OPENAI_API_KEY=your-api-key-here
AZURE_OPENAI_ENDPOINT=https://your-instance.openai.azure.com/
AZURE_OPENAI_DEPLOYMENT=gpt-4o-mini
AZURE_OPENAI_API_VERSION=2024-02-15-preview
AZURE_OPENAI_MAX_RETRIES=3
AZURE_OPENAI_TIMEOUT=60
# Chroma Vector Database (On-Premises)
CHROMA_HOST=chroma-server.internal.company.com
CHROMA_PORT=8000
CHROMA_COLLECTION=innovation_embeddings
CHROMA_SIMILARITY_THRESHOLD=0.75
CHROMA_MAX_RESULTS=5
CHROMA_TIMEOUT=10
# Elasticsearch Configuration (On-Premises)
ES_HOSTS=["es-node1.internal:9200","es-node2.internal:9200"]
ES_INDEX=innovation_documents
ES_USERNAME=elastic_user
ES_PASSWORD=secure_password
ES_USE_SSL=true
ES_VERIFY_CERTS=true
ES_TIMEOUT=30
# Azure Application Insights
APPINSIGHTS_INSTRUMENTATION_KEY=your-instrumentation-key
LOG_LEVEL=INFO
ENABLE_DISTRIBUTED_TRACING=true
TELEMETRY_SAMPLE_RATE=1.0
# Workflow Configuration
WORKFLOW_MAX_RETRIES=3
WORKFLOW_RETRY_DELAY=5
WORKFLOW_TIMEOUT=300
ENABLE_CHECKPOINTING=true
CHECKPOINT_BACKEND=redis
REDIS_URL=redis://redis-server.internal:6379/0
```
### Docker Compose for Hybrid Deployment
**docker-compose.yml** (On-Premises Components)
```yaml
version: '3.8'
services:
# Chroma vector database
chroma:
image: chromadb/chroma:latest
container_name: chroma-server
ports:
- "8000:8000"
volumes:
- chroma_data:/chroma/chroma
environment:
- IS_PERSISTENT=TRUE
- ANONYMIZED_TELEMETRY=FALSE
networks:
- extraction_network
# Redis for LangGraph checkpointing
redis:
image: redis:7-alpine
container_name: redis-checkpoint
ports:
- "6379:6379"
volumes:
- redis_data:/data
command: redis-server --appendonly yes
networks:
- extraction_network
# Workflow application
extraction_workflow:
build: .
container_name: extraction-workflow
depends_on:
- chroma
- redis
environment:
- CHROMA_HOST=chroma
- REDIS_URL=redis://redis:6379/0
env_file:
- .env
networks:
- extraction_network
restart: unless-stopped
volumes:
chroma_data:
redis_data:
networks:
extraction_network:
driver: bridge
```
Key Production Patterns Demonstrated
1. **Configuration Management:** Pydantic-based settings with environment variable validation
2. **Comprehensive Telemetry:** Application Insights integration with distributed tracing
3. **Error Handling:** Retry logic with exponential backoff, graceful degradation
4. **State Validation:** Runtime schema validation using Pydantic models
5. **Hybrid Retrieval:** Elasticsearch (on-prem) + Chroma (on-prem) with fallback logic
6. **LLM Resilience:** Rate limit handling, token tracking, latency monitoring
7. **Workflow Checkpointing:** Redis-backed state persistence for long-running workflows
8. **Observability Hooks:** Metrics, logs, and traces at every critical decision point
9. **Cross-Environment Correlation:** Correlation IDs propagated through entire pipeline
10. **Production Deployment:** Docker Compose example for on-premises components
With the code implementation outlined above providing a practical foundation for deploying an AI-powered data extraction model in a hybrid Azure and on-premises environment, the critical challenge shifts from initial setup to maintaining operational reliability and extraction fidelity at scale.
In production, a system faces distinct failure modes and degradation patterns shaped by its distributed architecture:
To establish robust monitoring practices tailored to these hybrid, LLM-driven operational realities we will explore in part 2 of the Blog.