
ISA 315 (Revised 2019) requires risk assessment to be cumulative yet most audit tooling treats each engagement year as a clean slate. This paper introduces the Connected Engagement History (CEH): a temporal knowledge graph that operationalises that obligation by linking past audit narratives, repeat findings, auditor continuity, and rolling financial signals into a single reasoning structure. Risk profiles are built on longitudinal context, not point-in-time outliers surfaced through a DeBERTa-v3-large classifier, an LSTM-Attention model with temporally indexed Attribution Maps, and a hallucination-constrained Graph-RAG advisory layer, in direct correspondence with ISA 315.R paragraphs 19–27.
Every significant audit failure shares the same structural blind spot: the risk model saw what was happening in the current period but had no memory of how it got there. A revenue recognition anomaly in Year 5 is a very different signal when three prior engagements flagged management override of controls, quarter-end journal entries above materiality, and auditor turnover all of which were recorded in disconnected Word documents, Excel workpapers, and scanned PDF management letters that no model was ever trained to read together.
Standard anomaly detection methods Z-score thresholds, Benford's Law tests, IQR-based outlier flags are fundamentally cross-sectional. They take a single temporal slice of a client's financial data and measure it against a population distribution at that moment. The model has no axis for time, no capacity to observe trajectory, and no memory of what the same client looked like one, three, or five engagements ago. A receivables aging figure is evaluated against an industry peer mean, not against the same client's own prior-year baseline or the pattern that preceded their last material misstatement.
This cross-sectional design is not an implementation choice it is a structural constraint. You cannot ask a Z-score "Has this client shown a gradually escalating pattern of control exceptions over four years?" or "Does today's revenue concentration risk look like it did 24 months before the prior write-off?" because those are longitudinal questions. They require an observation window, not an observation point. The shift from cross-sectional anomaly detection to longitudinal risk profiling is the precise architectural problem that the Connected Engagement History (CEH) is designed to solve and it is why a graph, with its native support for typed, time-stamped relationships across entities, is the right data structure to build it on

A Connected Engagement History is not a relational database of past engagements. It is a temporal knowledge graph where nodes represent entities clients, engagements, findings, auditors, financial periods, assertions and edges represent typed, time-stamped relationships with confidence weights.
The architecture rests on one critical design principle: every node carries both structured attributes (financial ratios, risk ratings, materiality thresholds) and unstructured embeddings (semantic vectors from prior year management letters, going concern paragraphs, and audit narratives). These two modalities are kept deliberately separate through the ingestion, graph construction, and feature engineering stages they are only combined at the point of model inference. This is a late fusion design.
The choice is intentional and addresses a well-documented failure mode in multimodal models: when high-dimensional financial signals and narrative embeddings are concatenated early in the pipeline an early fusion approach the numerical features, which carry significantly higher variance and volume, systematically suppress the lower-magnitude semantic signals. A going concern caveat buried in paragraph four of a management letter produces an embedding shift of perhaps 0.03 on a given dimension. A revenue growth outlier moves a financial feature by orders of magnitude more. Early fusion allows the louder signal to win by default.
Late fusion prevents this by allowing each modality to develop its own representational depth independently, then combining their outputs at the classifier layer where both carry equal structural weight. The result is a model that can treat a subtle but consistent shift in audit narrative tone from process-focused language toward control-environment language across three engagements as an equally valid risk signal to a deteriorating Altman Z-score.

Think of it as the difference between a doctor who reads only today's lab results and one who reads the full patient history before interpreting them. The numbers are identical. The clinical judgment is not.
The pipeline has five stages that work in sequence:
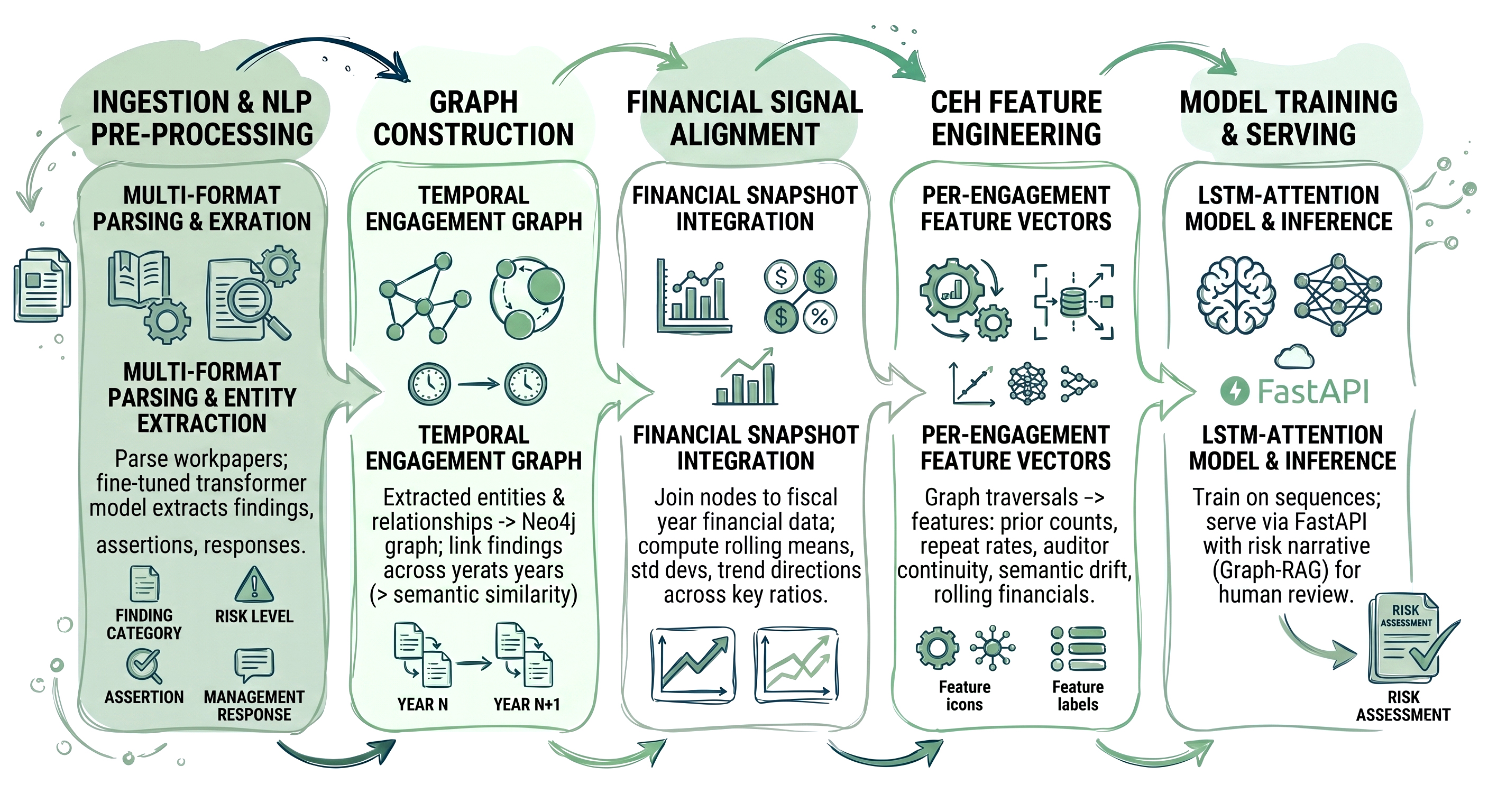
1. Ingestion and NLP Pre-processing: Multi-format workpapers are parsed; audit-specific entities (finding category, risk level, assertion, management response) are extracted using a fine-tuned transformer model
2. Graph Construction: Extracted entities and relationships are written into a Neo4j temporal engagement graph, with findings linked across years where semantic similarity exceeds a threshold
3. Financial Signal Alignment: Each engagement node is joined to a computed financial snapshot for the corresponding fiscal year, including rolling means, standard deviations, and trend directions across key ratios
4. CEH Feature Engineering: Graph traversals produce per-engagement feature vectors encoding prior finding counts, repeat-finding rates, auditor continuity, semantic drift in narrative themes, and rolling financial context
5. Model Training and Serving: An LSTM-Attention model trains on the feature sequences; inference is served via a FastAPI endpoint that also returns a Graph-RAG-generated risk narrative for human review
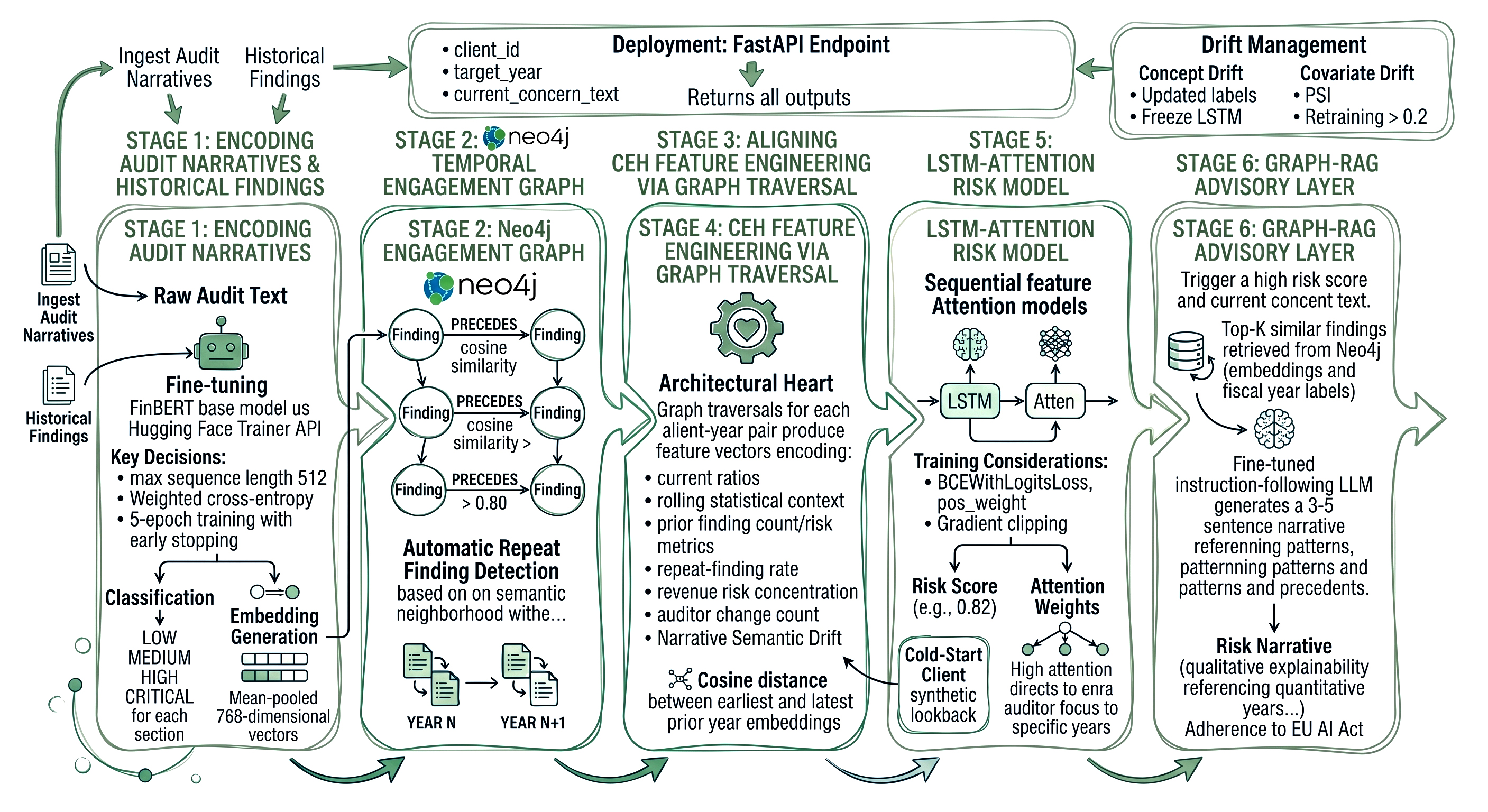
Off-the-shelf FinBERT understands financial sentiment but not audit-specific risk language. The phrase "management representation obtained regarding cut-off" reads neutrally to a general model but signals a potential completeness assertion risk to a trained auditor. Fine-tuning on a labelled corpus of prior findings mapped to [LOW, MEDIUM, HIGH, CRITICAL] risk levels produces a classifier that understands the domain.
The tokenisation and training setup follows the standard Hugging Face Trainer API with a ProsusAI/finbert base. The key training decisions are:
After fine-tuning, the model serves two purposes: classification (risk label for each section) and embedding generation via mean-pooled last hidden states. These 768-dimensional vectors become the semantic properties stored on Finding nodes in the graph.
The graph schema is purpose-built for temporal traversals — the queries that power CEH feature engineering all ask "what happened across years" rather than "what does this period look like".
// Core node types and a sample engagement-finding chain
CREATE (:Client {client_id: "CL-001", industry_code: "SIC-5912", risk_tier: "TIER_2"})
CREATE (:Engagement {
engagement_id: "ENG-2022-CL001",
fiscal_year: 2022,
opinion_type: "UNMODIFIED",
materiality_threshold: 500000.0
})
CREATE (:Finding {
finding_id: "FND-2022-CL001-003",
category: "REVENUE_RECOGNITION",
risk_level: "HIGH",
narrative_embedding: [0.12, -0.33, /* ... 768 dims */],
repeat_finding: false
})
// Temporal relationship between consecutive findings of the same theme
MATCH (f1:Finding {finding_id: "FND-2021-CL001-002"})
MATCH (f2:Finding {finding_id: "FND-2022-CL001-003"})
CREATE (f1)-[:PRECEDES {similarity_score: 0.87, theme:
"REVENUE_RISK"}]->(f2)
The PRECEDES relationship is the most important edge in the graph. It is created programmatically by computing cosine similarity between finding embeddings across fiscal years for the same client. A raw similarity score above 0.80 means the same underlying risk theme resurfaced in a new engagement the textual language may be different, but the semantic neighbourhood is the same. This is how the system detects repeat findings without relying on a human to tag them as such.
However, raw cosine similarity alone produces a flat graph it treats a repeat finding from six years ago with the same predictive weight as one from last year. That is not how risk compounds. A control deficiency that was flagged, remediated, and has not reappeared for five years is materially different from one that resurfaced twelve months ago. To reflect this, the PRECEDES relationship stores a temporally decayed similarity score computed as:

where Δ𝑡 is the gap in fiscal years between the two linked findings and λ is a decay rate hyperparameter. A value of λ=0.15 produces a half-life of approximately 4.6 years meaning a finding from five years ago retains roughly 47% of its original similarity weight, while one from last year retains 86%. This decayed score is what gets stored on the edge as similarity_score and subsequently used in the CEH feature engineering traversal and the Graph-RAG precedent retrieval ranking. λ is treated as a tunable hyperparameter during model validation, allowing firms to adjust decay aggressiveness based on their client portfolio's typical remediation cycle length.
Automatic Repeat Finding Detection
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def detect_and_link_repeats(session, client_id: str, threshold: float = 0.80):
results = session.run("""
MATCH (c:Client {client_id: $cid})-[:HAS_ENGAGEMENT]->(e:Engagement)
MATCH (e)-[:CONTAINS_FINDING]->(f:Finding)
RETURN f.finding_id AS fid, e.fiscal_year AS fy, f.narrative_embedding AS emb
ORDER BY fy ASC
""", cid=client_id).data()
for i in range(len(results)):
for j in range(i + 1, len(results)):
if results[j]["fy"] <= results[i]["fy"]:
continue
sim = cosine_similarity([results[i]["emb"]], [results[j]["emb"]])[0][0]
if sim >= threshold:
session.run("""
MATCH (f1:Finding {finding_id: $a}), (f2:Finding {finding_id: $b})
MERGE (f1)-[r:PRECEDES]->(f2)
SET r.similarity_score = $sim
""", a=results[i]["fid"], b=results[j]["fid"], sim=float(sim))
This runs as a post-ingestion job each time a new engagement is loaded. It does not require auditors to manually flag recurrence the graph discovers it from the semantic structure of the language itself.
Every engagement node must be paired with a financial snapshot for its fiscal year. The snapshot is not just the current-period ratios it includes rolling context features computed across the trailing window:
These computed features are written back into the graph as FinancialPeriod nodes linked to the corresponding Client and Engagement nodes. The financial layer and the narrative layer then become jointly queryable in a single Cypher traversal the combination that makes CEH feature vectors meaningfully different from anything a flat table can produce.
The Connected Engagement History architecture turns ISA 315’s cumulative risk assessment requirement into something a machine can operationalise. Instead of treating each audit as an isolated statistical exercise, CEH encodes the client’s narrative and numerical history into a temporal knowledge graph: findings, financial trajectories, auditor continuity, remediation cycles, and their semantic drift over time all become first-class objects in the data model.
By the end of this first part, three structural constraints of traditional tooling have been removed. We are no longer limited to cross-sectional anomaly tests; we can reason longitudinally across years. We are no longer forced to collapse narratives into free-text attachments; they are embedded, indexed, and connected. And we are no longer dependent on static ratio tables; financial signals are aligned to engagements with rolling context and temporal decay.
Part 2 builds directly on this foundation. It shows how to turn this graph into a working predictive system: constructing CEH feature vectors via graph traversal, training an LSTM-based risk model with temporally indexed Attribution Maps, wrapping the whole stack in a hallucination-constrained Graph-RAG layer, and deploying it with drift monitoring and shadow releases that are acceptable in a regulated audit environment.